async raft
![]()


![]()


Blazing fast Rust, a modern consensus protocol, and a reliable async runtime — this project intends to provide a consensus backbone for the next generation of distributed data storage systems (SQL, NoSQL, KV, Streaming, Graph ... or maybe something more exotic).
The guide is the best place to get started, followed by the docs for more in-depth details.
This crate differs from other Raft implementations in that:
- It is fully reactive and embraces the async ecosystem. It is driven by actual Raft events taking place in the system as opposed to being driven by a
tickoperation. Batching of messages during replication is still used whenever possible for maximum throughput. - Storage and network integration is well defined via two traits
RaftStorage&RaftNetwork. This provides applications maximum flexibility in being able to choose their storage and networking mediums. See the storage & network chapters of the guide for more details. - All interaction with the Raft node is well defined via a single public
Rafttype, which is used to spawn the Raft async task, and to interact with that task. The API for this system is clear and concise. See the raft chapter in the guide. - Log replication is fully pipelined and batched for optimal performance. Log replication also uses a congestion control mechanism to help keep nodes up-to-date as efficiently as possible.
- It fully supports dynamic cluster membership changes according to the Raft spec. See the
dynamic membershipchapter in the guide. With full support for leader stepdown, and non-voter syncing. - Details on initial cluster formation, and how to effectively do so from an application's perspective, are discussed in the cluster formation chapter in the guide.
- Automatic log compaction with snapshots, as well as snapshot streaming from the leader node to follower nodes is fully supported and configurable.
- The entire code base is instrumented with tracing. This can be used for standard logging, or for distributed tracing, and the verbosity can be statically configured at compile time to completely remove all instrumentation below the configured level.
This implementation strictly adheres to the Raft spec (pdf warning), and all data models use the same nomenclature found in the spec for better understandability. This implementation of Raft has integration tests covering all aspects of a Raft cluster's lifecycle including: cluster formation, dynamic membership changes, snapshotting, writing data to a live cluster and more.
If you are building an application using this Raft implementation, open an issue and let me know! I would love to add your project's name & logo to a users list in this project.
contributing
Check out the CONTRIBUTING.md guide for more details on getting started with contributing to this project.
license
async-raft is licensed under the terms of the MIT License or the Apache License 2.0, at your choosing.
NOTE: the appearance of the "section" symbols § throughout this project are references to specific sections of the Raft spec.
Getting Started
Raft is a distributed consensus protocol designed to manage a replicated log containing state machine commands from clients. Why use Raft? Among other things, it provides data storage systems with fault-tolerance, strong consistency and linearizability.
A visual depiction of how Raft works (taken from the spec) can be seen below.
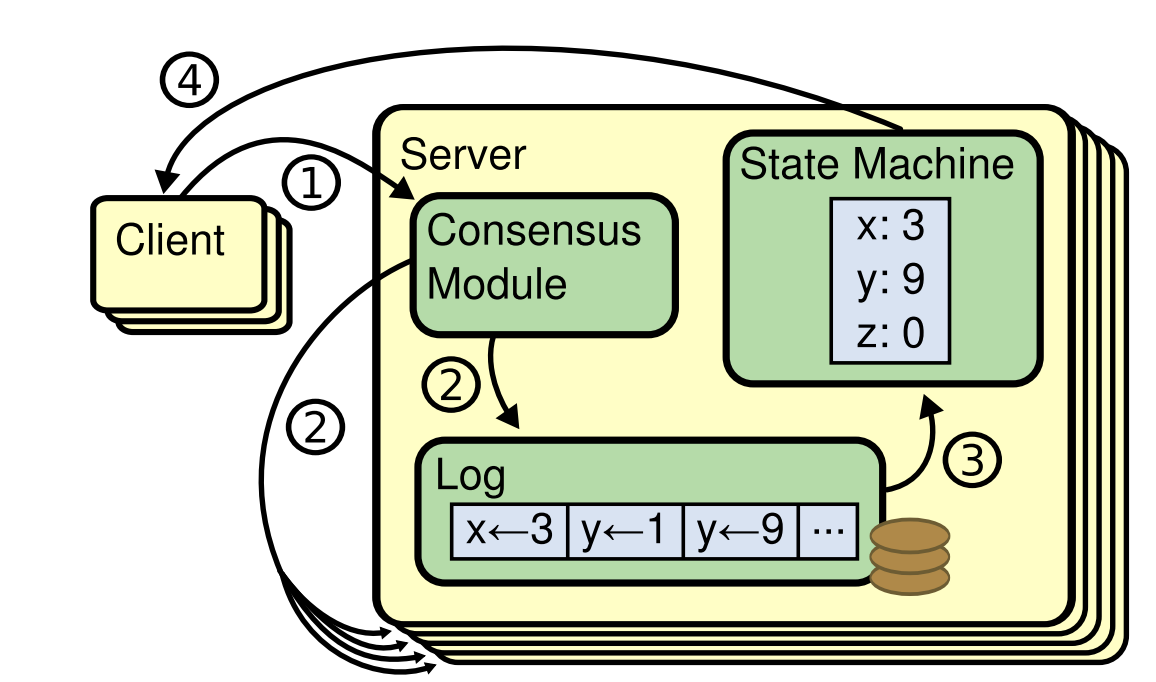
Raft is intended to run within some parent application, which traditionally will be some sort of data storage system (SQL, NoSQL, KV store, AMQP, Streaming, Graph, whatever). You can do whatever you want with your application, Raft will provide you with the consensus module.
first steps
In order to start using Raft, you will need to declare the data types you will use for client requests and client responses. Let's do that now. Throughout this guide, we will be using the memstore crate, which is an in-memory implementation of the RaftStorage trait for demo and testing purposes (part of the same repo). This will give us a concrete set of examples to work with, which also happen to be used for all of the integration tests of async-raft itself.
async_raft::AppData
This marker trait is used to declare an application's data type. It has the following constraints: Clone + Debug + Send + Sync + Serialize + DeserializeOwned + 'static. Your data type represents the requests which will be sent to your application to create, update and delete data. Requests to read data should not be sent through Raft, only mutating requests. More on linearizable reads, and how to avoid stale reads, is discussed in the Raft API chapter.
The intention of this trait is that applications which are using this crate will be able to use their own concrete data types throughout their application without having to serialize and deserialize their data as it goes through Raft. Instead, applications can present their data models as-is to Raft, Raft will present it to the application's RaftStorage impl when ready, and the application may then deal with the data directly in the storage engine without having to do a preliminary deserialization.
impl
Finishing up this step is easy, just impl AppData for YourData {} ... and in most cases, that's it. You'll need to be sure that the aforementioned constraints are satisfied on YourData. The following derivation should do the trick #[derive(Clone, Debug, Serialize, Deserialize)].
In the memstore crate, here is a snippet of what the code looks like:
#![allow(unused)] fn main() { /// The application data request type which the `MemStore` works with. /// /// Conceptually, for demo purposes, this represents an update to a client's status info, /// returning the previously recorded status. #[derive(Clone, Debug, Serialize, Deserialize)] pub struct ClientRequest { /* fields omitted */ } impl AppData for ClientRequest {} }
async_raft::AppDataResponse
This marker trait is used to declare an application's response data. It has the following constraints: Clone + Debug + Send + Sync + Serialize + DeserializeOwned + 'static.
The intention of this trait is that applications which are using this crate will be able to use their own concrete data types for returning response data from the storage layer when an entry is applied to the state machine as part of a client request (this is not used during replication). This allows applications to seamlessly return application specific data from their storage layer, up through Raft, and back into their application for returning data to clients.
This type must encapsulate both success and error responses, as application specific logic related to the success or failure of a client request — application specific validation logic, enforcing of data constraints, and anything of that nature — are expressly out of the realm of the Raft consensus protocol.
impl
Finishing up this step is also easy: impl AppDataResponse for YourDataResponse {}. The aforementioned derivation applies here as well.
In the memstore crate, here is a snippet of what the code looks like:
#![allow(unused)] fn main() { /// The application data response type which the `MemStore` works with. #[derive(Clone, Debug, Serialize, Deserialize)] pub struct ClientResponse(Result<Option<String>, ClientError>); impl AppDataResponse for ClientResponse {} }
Woot woot! Onward to the networking layer.
Network
Raft is a distributed consensus protocol, so the ability to send and receive data over a network is integral to the proper functionality of nodes within a Raft cluster.
The network capabilities required by this system are broken up into two parts: the RaftNetwork trait & the application network.
RaftNetwork
Raft uses the RaftNetwork trait for sending Raft RPCs. This trait says nothing about how those requests should be received on the other end. There is a lot of flexibility with this trait. Maybe you want to use Tonic gRPC, or perhaps some other HTTP-based protocol. One could use WebSockets, a raw TCP socket, UDP, HTTP3 ... in the end, this depends on the application's needs. Whichever option is chosen, the fundamental requirement is that an implementor of the RaftNetwork trait must be able to reliably transmit data over the network.
All of the methods to be implemented are similar in structure. Take this one for example:
#![allow(unused)] fn main() { /// Send an AppendEntries RPC to the target Raft node (§5). async fn append_entries(&self, target: NodeId, rpc: AppendEntriesRequest<D>) -> Result<AppendEntriesResponse>; }
The implementing type should use the given NodeId (just a u64) to identify the target Raft node to which the given rpc must be sent. For applications using a single Raft cluster, this is quite simple. If using a multi-Raft setup, cluster information could be embedded in the RaftNetwork implementing type, and network requests could be enriched with that cluster information before being transmitted over the network to ensure that the receiving server can pass the received rpc to the correct Raft cluster.
The excellent async_trait crate is re-exported by this crate to make implementation as easy as possible. Please see the documentation on how to use this macro to creating an async trait implementation.
Application Network
The main role of the application network, in this context, is to handle RPCs from Raft peers and client requests coming from application clients, and then feed them into Raft. This is essentially the receiving end of the RaftNetwork trait, however this project does not enforce any specific interface on how this is to be implemented. The only requirement is that it work with the RaftNetwork trait implementation. There are a few other important things that it will probably need to do as well, depending on the application's needs, here are a few other common networking roles:
- discovery: a component which allows the members of an application cluster (its nodes) to discover and communicate with each other. This is not provided by this crate. There are lots of solutions out there to solve this problem. Applications can build their own discovery system by way of DNS, they could use other systems like etcd or consul. The important thing to note here is that once a peer is discovered, it would be prudent for application nodes to maintain a connection with that peer, as heartbeats are very regular, and building new network connections is not free.
- data format: the way that data is serialized and sent accross the networking medium. Popular data formats include protobuf, capnproto, flatbuffers, message pack, JSON &c. Applications are responsible for serializing and deserializing the various message types used in this crate for network transmission. Serde is used throughout this system to aid on this front.
Applications must be able to facilitate message exchange between nodes reliably.
Now that we've got a solid taste for the network requirements, let's move on to Raft storage.
Storage
The way that data is stored and represented is an integral part of every data storage system. Whether it is a SQL or NoSQL database, a KV store, an AMQP / Streaming / Eventing system, a Graph database, or anything which stores data — control over the storage technology and technique is critical. This implementation of Raft uses the RaftStorage trait to define the behavior needed of an application's storage layer to work with Raft.
implementation
There are a few important decisions which need to be made in order to implement the RaftStorage trait.
- How do you plan on storing your snapshots? The
RaftStorage::Snapshotassociated type must declare the type your application uses for dealing with the raw bytes of a snapshot. For most applications, it stands to reason that a simple on-disk file is what will be used. As such, take a look at Tokio's fs::File. It satisfies all of the trait bounds for theSnapshotassociated type. - How do you plan on storing your data? A majority of the methods of your
RaftStorageimpl will involve reading and writing data. Rust has a few data storage crates available to choose from which will satisfy these requirements. Have a look at Sled, or RocksDB. There are others to choose from, but these may be a solid starting point. Or you could always roll your own.
Once you're ready to begin with your implementation, be sure to adhere to the documentation of the RaftStorage methods themselves. There are plenty of data safety requirements to uphold in order for your application to work properly overall, and to work properly with Raft.
For inspiration, have a look at this repo's memstore project. It is an in-memory implementation of the RaftStorage trait, intended for demo and testing purposes.
compaction / snapshots
This implementation of Raft automatically triggers log compaction based on runtime configuration, using the RaftStorage::do_log_compaction method. Everything related to compaction / snapshots starts with this method. Though snapshots are originally created in the RaftStorage::do_log_compaction method, the Raft cluster leader may stream a snapshot over to other nodes if the node is new and needs to be brought up-to-speed, or if a node is lagging behind. Internally, Raft uses the RaftStorage::Snapshot associated type to work with the snapshot locally and for streaming to follower nodes.
Compaction / snapshotting are not optional in this system. It is an integral component of the Raft spec, and RaftStorage implementations should be careful to implement the compaction / snapshotting related methods carefully according to the trait's documentation.
When performing log compaction, the compaction can only cover the breadth of the log up to the last applied log and under write load this value may change quickly. As such, the storage implementation should export/checkpoint/snapshot its state machine, and then use the value of that export's last applied log as the metadata indicating the breadth of the log covered by the snapshot.
There is more to learn, so let's keep going. Time to learn about the most central API of this project.
Raft API
The Raft type represents the singular API of this crate, and is the interface to a running Raft node. It is highly generic, which allows your application's data types to be known at compile, for maximum performance and type-safety. Users of this Raft implementation get to choose the exact types to be used throughout the system, and get to work with their application's data types directly without the overhead of serializing and deserializing the data as it moves through the Raft system.
In previous chapters, we've defined our AppData, AppDataResponse, RaftNetwork and RaftStorage types. These four types are used as part of a concrete Raft definition, and applications may find it beneficial to define an alias covering all of these types for easier reference. Something like the following:
#![allow(unused)] fn main() { /// Your Raft type alias. type YourRaft = Raft<YourData, YourDataResponse, YourRaftNetwork, YourRaftStorage>; }
API
The API of the Raft type is broken up into 4 sections: Client Requests, Raft RPCs, Admin Commands & Utility Methods.
Client Requests
The application level interface for clients is 100% at the discression of the application being built. However, once a client read or write operation is ready to be processed, the below methods provide the read/write functionality for Raft interaction.
async fn client_read(...) -> Result<...>: Check to ensure this node is still the cluster leader, in order to guard against stale reads. The actual read operation itself is up to the application, this method just ensures that the read will not be stale.async fn client_write(...) -> Result<...>: Submit a mutating client request to Raft to update the state of the system (§5.1). It will be appended to the log, committed to the cluster, and then applied to the application state machine. The result of applying the request to the state machine will be returned as the response from this method.
Raft RPCs
These methods directly correspond to the RaftNetwork trait described in earlier chapters. The application is responsible for implementing its own network layer which can receive these RPCs coming from Raft peers, and should then pass them into the Raft node using the following methods.
async fn append_entries(...) -> Result<...>: An RPC invoked by the leader to replicate log entries (§5.3); also used as heartbeat (§5.2).async fn vote(...) -> Result<...>: An RPC invoked by candidates to gather votes (§5.2).async fn install_snapshot(...) -> Result<...>: Invoked by the Raft leader to send chunks of a snapshot to a follower (§7).
Admin Commands
All of these methods are intended for use directly by the parent application for managing various lifecycles of the cluster. Each of these lifecycles are discussed in more detail in the Cluster Controls chapter.
async fn initialize(...) -> Result<...>: Initialize a pristine Raft node with the given config & start a campaign to become leader.async fn add_non_voter(...) -> Result<...>: Add a new node to the cluster as a non-voter, which will sync the node with the master so that it can later join the cluster as a voting member.async fn change_membership(...) -> Result<...>: Propose a new membership config change to a running cluster.
Utility Methods
fn metrics(&self) -> watch::Receiver<RaftMetrics>: Get a stream of all metrics coming from the Raft node.fn shutdown(self) -> tokio::task::JoinHandle<RaftResult<()>>: Send a shutdown signal to the Raft node, and get aJoinHandlewhich can be used to await the full shutdown of the node. If the node is already in shutdown, this routine will allow you to await its full shutdown.
Reading & Writing Data
What does the Raft spec have to say about reading and writing data?
Clients of Raft send all of their requests to the leader. When a client first starts up, it connects to a randomly-chosen server. If the client’s first choice is not the leader, that server will reject the client’s request and supply information about the most recent leader it has heard from. If the leader crashes, client requests will timeout; clients then try again with randomly-chosen servers.
The Raft.metrics method, discussed above, provides a stream of data on the Raft node's internals, and should be used in order to determine the cluster leader, which should only need to be performed once when the client connection is first established.
Our goal for Raft is to implement linearizable semantics (each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response). [...] if the leader crashes after committing the log entry but before responding to the client, the client [may] retry the command with a new leader, causing it to be executed a second time. The solution is for clients to assign unique serial numbers to every command. Then, the state machine tracks the latest serial number processed for each client, along with the associated response. If it receives a command whose serial number has already been executed, it responds immediately without re-executing the request.
As described in the quote above, applications will need to have their clients assign unique serial numbers to every command sent to the application servers. Then, within the application specific code implemented inside of RaftStorage::apply_entry_to_state_machine, if the application detects that the serial number has already been executed for the requesting client, then the response should be immediately returned without re-executing the request. Much of this will be application specific, but these principals can help with design.
Read-only operations can be handled without writing anything into the log. However, with no additional measures, this would run the risk of returning stale data, since the leader responding to the request might have been superseded by a newer leader of which it is unaware. [...] a leader must check whether it has been deposed before processing a read-only request (its information may be stale if a more recent leader has been elected). Raft handles this by having the leader exchange heartbeat messages with a majority of the cluster before responding to read-only requests.
The Raft.client_read method should be used to ensure that the callee Raft node is still the cluster leader.
The API is simple enough, now its time to put everything together.
Putting It All Together
In previous chapters we've seen how to define our application's data types which will be used for interacting with Raft, we've seen how to implement the RaftNetwork trait, we've seen how to implement the RaftStorage trait, and we've reviewed the Raft API itself. Now its time to put all of these components together. Let's do this.
For this chapter, we're going to use snippets of the code found in the memstore crate, which is an in-memory implementation of the RaftStorage trait for demo and testing purposes, which also happens to be used for all of the integration tests of async-raft itself.
Recap On Our Data Types
As we've seen earlier, here are our AppData and AppDataResponse types/impls.
#![allow(unused)] fn main() { /// The application data request type which the `MemStore` works with. /// /// Conceptually, for demo purposes, this represents an update to a client's status info, /// returning the previously recorded status. #[derive(Serialize, Deserialize, Debug, Clone)] pub struct ClientRequest { /// The ID of the client which has sent the request. pub client: String, /// The serial number of this request. pub serial: u64, /// A string describing the status of the client. For a real application, this should probably /// be an enum representing all of the various types of requests / operations which a client /// can perform. pub status: String, } impl AppData for ClientRequest {} /// The application data response type which the `MemStore` works with. #[derive(Serialize, Deserialize, Debug, Clone)] pub struct ClientResponse(Result<Option<String>, ClientError>); impl AppDataResponse for ClientResponse {} }
RaftNetwork impl
We've already discussed the RaftNetwork trait in a previous chapter. Here is an abbreviated snippet of what the RaftNetwork impl looks like in the async-raft integration test suite.
#![allow(unused)] fn main() { // We use anyhow::Result in our impl below. use anyhow::Result; /// A type which emulates a network transport and implements the `RaftNetwork` trait. pub struct RaftRouter { // ... some internal state ... } #[async_trait] impl RaftNetwork<ClientRequest> for RaftRouter { /// Send an AppendEntries RPC to the target Raft node (§5). async fn append_entries(&self, target: u64, rpc: AppendEntriesRequest<ClientRequest>) -> Result<AppendEntriesResponse> { // ... snip ... } /// Send an InstallSnapshot RPC to the target Raft node (§7). async fn install_snapshot(&self, target: u64, rpc: InstallSnapshotRequest) -> Result<InstallSnapshotResponse> { // ... snip ... } /// Send a RequestVote RPC to the target Raft node (§5). async fn vote(&self, target: u64, rpc: VoteRequest) -> Result<VoteResponse> { // ... snip ... } } }
RaftStorage impl
We've already got a RaftStorage impl to work with from the memstore crate. Here is an abbreviated snippet of the code.
#![allow(unused)] fn main() { // We use anyhow::Result in our impl below. use anyhow::Result; #[async_trait] impl RaftStorage<ClientRequest, ClientResponse> for MemStore { type Snapshot = Cursor<Vec<u8>>; type ShutdownError = ShutdownError; async fn get_membership_config(&self) -> Result<MembershipConfig> { // ... snip ... } async fn get_initial_state(&self) -> Result<InitialState> { // ... snip ... } // The remainder of our methods are implemented below. // ... snip ... } }
Raft Type Alias
For better readability in your application's code, it would be beneficial to define a type alias which fully qualifies all of the types which your Raft instance will be using. This is quite simple. The example below is taken directly from this project's integration test suite, which uses the memstore crate and a specialized RaftNetwork impl designed specifically for testing.
#![allow(unused)] fn main() { /// A concrete Raft type used during testing. pub type MemRaft = Raft<ClientRequest, ClientResponse, RaftRouter, MemStore>; }
Give It The Boot
Though applications will be much more complex than this contrived example, booting a Raft node is dead simple. Even if your application uses a multi-Raft pattern for managing different segments / shards of data, the same principal applies. Boot a Raft node, and retain its instance for API usage.
//! This code assumes the code samples above. #[tokio::main] async fn main() { // Get our node's ID from stable storage. let node_id = get_id_from_storage().await; // Build our Raft runtime config, then instantiate our // RaftNetwork & RaftStorage impls. let config = Arc::new(Config::build("primary-raft-group".into()) .validate() .expect("failed to build Raft config")); let network = Arc::new(RaftRouter::new(config.clone())); let storage = Arc::new(MemStore::new(node_id)); // Create a new Raft node, which spawns an async task which // runs the Raft core logic. Keep this Raft instance around // for calling API methods based on events in your app. let raft = Raft::new(node_id, config, network, storage); run_app(raft).await; // This is subjective. Do it your own way. // Just run your app, feeding Raft & client // RPCs into the Raft node as they arrive. }
You've officially ascended to the next level of AWESOME! Next, let's take a look at cluster lifecycle controls, dynamic membership, and the like.
Cluster Controls
Raft nodes may be controlled in various ways outside of the normal flow of the Raft protocol using some of the API methods of the Raft type. This allows the parent application — within which the Raft node is running — to influence the Raft node's behavior based on application level needs.
concepts
In the world of Raft consensus, there are a few aspects of a Raft node's lifecycle which are not directly dictated in the Raft spec. Cluster formation and the preliminary details of what would lead to dynamic cluster membership changes are a few examples of concepts not directly detailed in the spec. This implementation of Raft offers as much flexibility as possible to deal with such details in a way which is safe according to the Raft specification, but also in a way which preserves flexibility for the many different types of applications which may be implemented using Raft.
Cluster Formation
All Raft nodes, when they first come online in a pristine state, will enter into the NonVoter state, which is a completely passive state.
To form a new cluster, application nodes must call the Raft.initialize method with the IDs of all discovered nodes which are to be part of the cluster (including the ID of the running node). Or if the application is to run in a standalone / single-node manner, it may issue the command with only its own ID.
Raft.initialize
This method is used exclusively for the formation of new clusters. This command will fail if the node is not in the NonVoter state, or if the node's log index is greater than 0.
This will cause the Raft node to hold the given configuration in memory and then immediately perform the election protocol. For single-node clusters, the node will immediately become leader, for multi-node clusters it will submit RequestVote RPCs to all of the nodes in the given config list. NOTE WELL that it is safe for EVERY node in the cluster to perform this action in parallel when a new cluster is being formed. Once this process has been completed, the newly elected leader will append the given membership config data to the log, ensuring that the new configuration will be reckoned as the initial cluster configuration moving forward throughout the life of the cluster.
In order to ensure that multiple independent clusters aren't formed by prematurely calling the Raft.initialize method before all peers are discovered, it is recommended that applications adopt a configurable cluster_formation_delay setting. The value for such a configuration should simply be a few orders of magnitude greater than the amount of time it takes for all the nodes of a new cluster to come online and discover each other. There are alternative patterns which may be used. Ultimately, this is subject to the design of the application.
As a rule of thumb, when new nodes come online, the leader of an existing Raft cluster will eventually discover the node (via the application's discovery system), and in such cases, the application could call the Raft.add_non_voter method to begin syncing the new node with the cluster. Once it is finished syncing, then applications should call the Raft.change_membership method to add the new node as a voting member of the cluster. For removing nodes from the cluster, the leader should call Raft.change_membership with the updated config, no preliminary steps are needed. See the next section for more details on this subject.
Dynamic Membership
Throughout the lifecycle of a Raft cluster, nodes will come and go. New nodes may need to be added to the cluster for various application specific reasons. Nodes may experience hardware failure and end up going offline. This implementation of Raft offers two mechanisms for controlling these lifecycle events.
Raft.add_non_voter
This method will add a new non-voter to the cluster and will immediately begin syncing the node with the leader. This method may be called multiple times as needed. The Future returned by calling this method will resolve once the node is up-to-date and is ready to be added as a voting member of the cluster.
Raft.change_membership
This method will start a cluster membership change. If there are any new nodes in the given config which were not previously added as non-voters from an earlier call to Raft.add_non_voter, then those nodes will begin the sync process. It is recommended that applications always call Raft.add_non_voter first when adding new nodes to the cluster, as this offers a bit more flexibility. Once Raft.change_membership is called, it can not be called again until the reconfiguration process is complete (which is typically quite fast).
Cluster auto-healing — where cluster members which have been offline for some period of time are automatically removed — is an application specific behavior, but is fully supported via this dynamic cluster membership system. Simply call Raft.change_membership with the dead node removed from the membership set.
Cluster leader stepdown is also fully supported. Nothing special needs to take place. Simply call Raft.change_membership with the ID of the leader removed from the membership set. The leader will recognize that it is being removed from the cluster, and will stepdown once it has committed the config change to the cluster according to the safety protocols defined in the Raft spec.
Metrics
Raft exports metrics on its internal state via the Raft.metrics method, which returns a stream of RaftMetrics. The metrics themselves describe the state of the Raft node, its current role in the cluster, its current membership config, as well as information on the Raft log and the last index to be applied to the state machine.
Applications may use this data in whatever way is needed. The obvious use cases are to expose these metrics to a metrics collection system, such as Prometheus, TimescaleDB, Influx &c. Applications may also use this data to trigger events within higher levels of the application itself.
Get To It
Rust is an outstanding language for building stateful systems.
- We don't need to continue allocating all of the memory of all of the clouds to the JVM.
- We ABSOLUTELY need to move away from all of the memory safety issues which have compromised countless systems.
- Raft is a robust and powerful consensus protocol, and this implementation offers a fairly robust API to build against.
There are plenty of awesome things to build! Let's do this!